Golang 正则匹配效率详解
最近有个小需求,校验IMEI是否为15位纯数字(是否合法)
以下是正则匹配与自己实现的简单验证方式进行压测
package mainimport ( 'regexp' 'testing')func BenchmarkIsDigitalRegexp(b *testing.B) { for i := 0; i < b.N; i++ { _ = isDigitalRegexp('358901806972417') }}func BenchmarkIsDigital(b *testing.B) { for i := 0; i < b.N; i++ { _ = isDigital('358901806972417') }}func isDigitalRegexp(imei string) bool { if ok, _ := regexp.Match('^[0-9]{15}$', []byte(imei)); ok { return true }else { return false }}func isDigital(imei string) bool { n := len(imei) if n == 15 { for i := 0; i < n; i++ { if imei[i] >= 48 && imei[i] <= 57 { continue }else { return false } } }else { return false } return true}压测结果:
C:UsersM709FJSAgosrcpprof_demore>go test -bench=. -benchmemgoos: windowsgoarch: amd64pkg: pprof_demo/reBenchmarkIsDigitalRegexp-12 300000 4644 ns/op 6450 B/op 70 allocs/opBenchmarkIsDigital-12 200000000 9.48 ns/op 0 B/op 0 allocs/opPASSok pprof_demo/re 4.577s
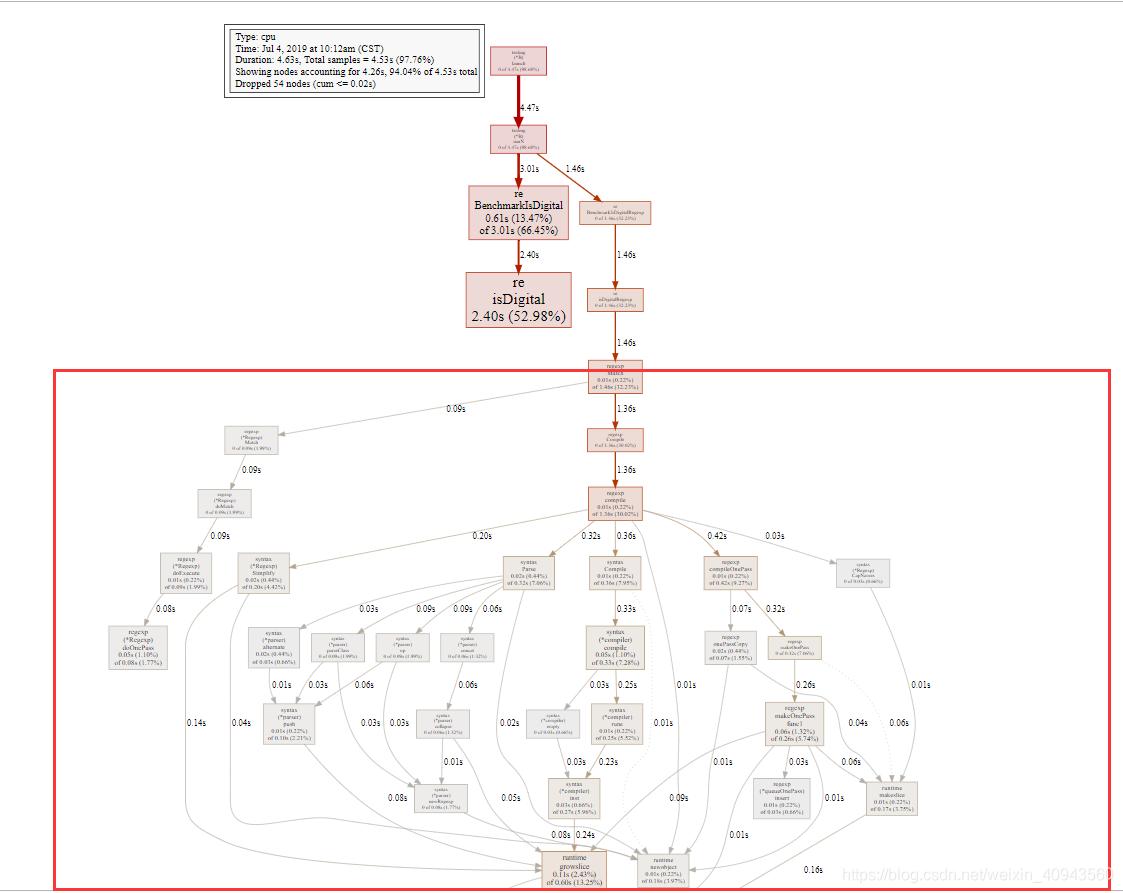
很明显,正则需要重新分配内存较多,从pprof生成图也可以看出,正则调用关系错综复杂
补充:Golang —— 正则表达式
正则表达式是一种进行模式匹配和文本操纵的复杂而又强大的工具。虽然正则表达式比纯粹的文本匹配效率低,但是它却更灵活。
按照它的语法规则,随需构造出的匹配模式就能够从原始文本中筛选出几乎任何你想要得到的字符组合。
Go语言通过regexp标准包为正则表达式提供了官方支持,如果你已经使用过其他编程语言提供的正则相关功能,那么你应该对Go语言版本的不会太陌生,但是它们之间也有一些小的差异,因为Go实现的是RE2标准,除了C。
其实字符串处理我们可以使用strings包来进行搜索(Contains、Index)、替换(Replace)和解析(Split、Join)等操作,但是这些都是简单的字符串操作,他们的搜索都是大小写敏感,而且固定的字符串,如果我们需要匹配可变的那种就没办法实现了,当然如果strings包能解决你的问题,那么就尽量使用它来解决。
因为他们足够简单、而且性能和可读性都会比正则好。
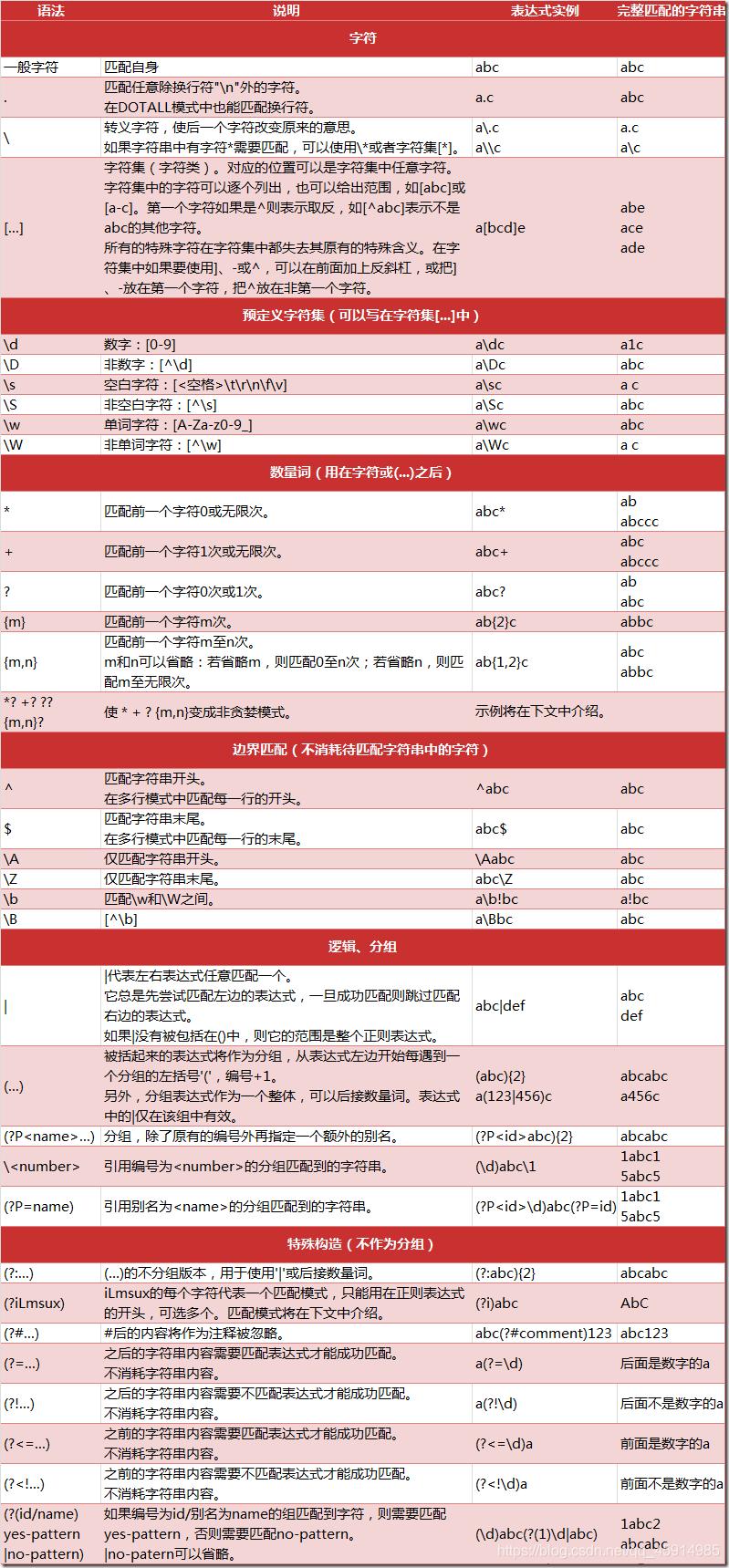
正则匹配规则图详细请参考官方文档
buf := 'abc azc a7c aac 888 a9c tac'// 1. 解释规则reg := regexp.MustCompile(`a.c`) // 这里会解析正则表达式,成功就返回解释器(. ——> 除n外任意字符)if reg == nil { // 解释失败fmt.Println('MustCompile err')return}// 2. 根据规则提取关键信息res := reg.FindAllStringSubmatch(buf, -1) //-1表示匹配所有的// res := reg.FindAllStringSubmatch(buf, 1) //1表示匹配一个fmt.Println('res = ', res)
执行结果:
res = [[abc] [azc] [a7c] [aac] [a9c]]2. 使用 […] (字符集) 匹配[0-9]之间的数值
buf := 'abc azc a7c aac 888 a9c tac' //1) 解释规则, 它会解析正则表达式,如果成功返回解释器 reg1 := regexp.MustCompile(`a[0-9]c`) if reg1 == nil { //解释失败,返回nil fmt.Println('MustCompile err') return } //2) 根据规则提取关键信息 result1 := reg1.FindAllStringSubmatch(buf, -1) fmt.Println('result1 = ', result1)
执行结果:
result1 = [[a7c] [a9c]]3. 使用 d 匹配[0-9]之间的数值
buf := 'abc azc a7c aac 888 a9c tac' //1) 解释规则, 它会解析正则表达式,如果成功返回解释器 reg1 := regexp.MustCompile(`adc`) if reg1 == nil { //解释失败,返回nil fmt.Println('MustCompile err') return } //2) 根据规则提取关键信息 result1 := reg1.FindAllStringSubmatch(buf, -1) fmt.Println('result1 = ', result1)
执行结果:
result1 = [[a7c] [a9c]]4.匹配小数
buf := '3.14 456 adsc as23d 1.23 3. 9.99 1lsa23d 0.08 0.00 ' // 解释正则表达式 reg := regexp.MustCompile(`d+.d+`) // +表示匹配前一个字符的一次或者多次 if reg == nil { fmt.Println('MustCompile err') return } // 提取关键信息 res := reg.FindAllStringSubmatch(buf, -1) fmt.Println('res = ', res)
执行结果:
res = [[3.14] [1.23] [9.99] [0.08] [0.00]]5.匹配信息中某关键字并过滤带标签的
// ` ` 是原生字符串buf := `<!DOCTYPE html><html lang='zh-CN'><head><title>Go语言标准库文档中文版 | Go语言中文网 | Golang中文社区 | Golang中国</title><meta name='viewport' content='width=device-width, initial-scale=1, maximum-scale=1.0, user-scalable=no'><meta http-equiv='X-UA-Compatible' content='IE=edge, chrome=1'><meta charset='utf-8'><link rel='shortcut icon' href='https://www.uahao.com/static/img/go.ico' rel='external nofollow' ><link rel='apple-touch-icon' type='image/png' href='https://www.uahao.com/static/img/logo2.png' rel='external nofollow' ><meta name='author' content='polaris <polaris@studygolang.com>'><meta name='keywords' content='中文, 文档, 标准库, Go语言,Golang,Go社区,Go中文社区,Golang中文社区,Go语言社区,Go语言学习,学习Go语言,Go语言学习园地,Golang 中国,Golang中国,Golang China, Go语言论坛, Go语言中文网'><meta name='description' content='Go语言文档中文版,Go语言中文网,中国 Golang 社区,Go语言学习园地,致力于构建完善的 Golang 中文社区,Go语言爱好者的学习家园。分享 Go 语言知识,交流使用经验'></head><div>和爱好</div><div>哈哈你在吗不在</div><div>测试</div><div>你过来啊</div><frameset cols='15,85'><frame src='https://rkxy.com.cn/static/pkgdoc/i.html'><frame name='main' src='https://rkxy.com.cn/static/pkgdoc/main.html' tppabs='main.html' ><noframes></noframes></frameset></html>`// 解释正则表达式reg := regexp.MustCompile(`<div>(?s:(.*?))</div>`) // s用来处理换行情况if reg == nil {fmt.Println('MustCompile err')return}// 提取关键字res := reg.FindAllStringSubmatch(buf, -1)// fmt.Println('res = ', res)// 过滤<> </>for _, text := range res {//fmt.Println('text[0] = ', text[0]) // 带<> </>的fmt.Println('text[1] = ', text[1]) // 不带<> </> 的}
执行结果:
text[1] = 和爱好text[1] = 哈哈 你在吗 不在 text[1] = 测试text[1] = 你过来啊
以上为个人经验,希望能给大家一个参考,也希望大家多多支持优爱好网。如有错误或未考虑完全的地方,望不吝赐教。
相关文章:
1. 怎么让div+css兼容ie6ie7ie8ie9和FireFoxChrome等浏览器2. requestAnimationFrame使用示例详解3. 基于JavaScript实现图片裁剪功能4. React优雅的封装SvgIcon组件示例5. uniapp自定义验证码输入框并隐藏光标6. 详解JavaScript中原始数据类型Symbol的使用7. JavaScript深拷贝方法structuredClone使用8. uniapp 手机验证码输入框实现代码(随机数、倒计时、隐藏手机号码中间四位)可以直接使用9. 使用Node.js实现Clean Architecture方法示例详解10. Jquery使用原生AJAX方法请求数据

 网公网安备
网公网安备