Oracle分析函数用法详解
一、概述
OLAP的系统(即Online Aanalyse Process)一般用于系统决策使用。通常和数据仓库、数据分析、数据挖掘等概念联系在一起。这些系统的特点是数据量大,对实时响应的要求不高或者根本不关注这方面的要求,以查询、统计操作为主。
我们来看看下面的几个典型例子:
①查找上一年度各个销售区域排名前10的员工
②按区域查找上一年度订单总额占区域订单总额20%以上的客户
③查找上一年度销售最差的部门所在的区域
④查找上一年度销售最好和最差的产品
我们看看上面的几个例子就可以感觉到这几个查询和我们日常遇到的查询有些不同,具体有:
- 需要对同样的数据进行不同级别的聚合操作
- 需要在表内将多条数据和同一条数据进行多次的比较
- 需要在排序完的结果集上进行额外的过滤操作
1、分析函数和聚合函数的不同之处是什么?
普通的聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。
2、分析函数的形式
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,他们的使用形式如下:
function_name(<argument>,<argument>...) over(<partition_Clause><order by_Clause><windowing_Clause>);
- function_name():函数名称
- argument:参数
- over( ):开窗函数
- partition_Clause:分区子句,数据记录集分组,group by...
- order by_Clause:排序子句,数据记录集排序,order by...
- windowing_Clause:开窗子句,定义分析函数在操作行的集合,三种开窗方式:rows、range、Specifying
注:使用开窗子句时一定要有排序子句!!!
3、OVER解析
OVER解析作用是告诉SQL引擎:按区域对数据进行分区,然后累积每个区域每个客户的订单总额(sum(sum(o.tot_sales)))。
①Over函数指明在那些字段上做分析,其内跟Partition by表示对数据进行分组。注意Partition by可以有多个字段。
②Over函数可以和其它聚集函数、分析函数搭配,起到不同的作用。例如这里的SUM,还有诸如Rank,Dense_rank等。
4、Oracle分析函数简单实例:
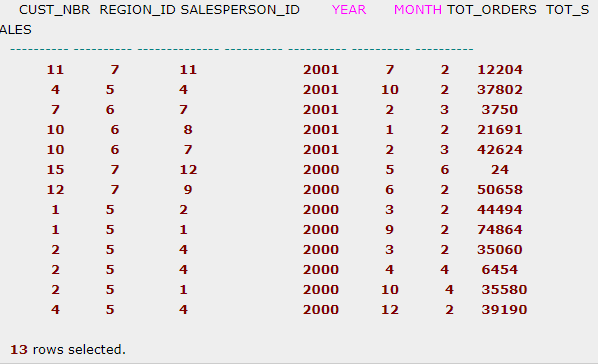
-- 按区域查找上一年度订单总额占区域订单总额20%以上的客户 table : orders_tmp
select * from orders_tmp;
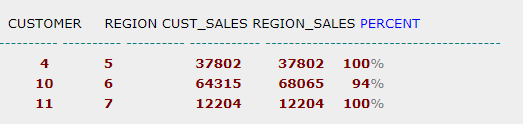
select cust_nbr, region_id, cust_sales, region_sales, -- 此处可以用tmptb.* , 但不能用 *
100 * round(cust_sales / region_sales, 2) || "%" Percent from
(select cust_nbr, region_id,
sum(TOT_SALES) cust_sales,
sum(sum(tot_sales)) over(partition by REGION_ID) as region_sales
from orders_tmp where o.year = 2001 group by CUST_NBR, REGION_ID order by REGION_ID) tmptb
where cust_sales > region_sales * 0.2;
二、分析函数:Rank, Dense_rank, row_number,Ntile() 排列
形式:
Rank() Over ([Partition by ] [Order by ] [Nulls First/Last]) Dense_rank() Over ([Patition by ] [Order by ] [Nulls First/Last]) Row_number() Over ([Partitionby ] [Order by ] [Nulls First/Last]) Ntile() Over ([Partition by ] [Order by ])
rank,dense_rank,row_number函数为每条记录产生一个从1开始至n的自然数,n的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。
- row_number: 返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
- dense_rank: 返回一个唯一的值,当碰到相同数据时,此时所有相同数据的排名都是一样的。first、last :从DENSE_RANK返回的集合中取出排在最后面的一个值的行
- rank: 返回一个唯一的值,当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
①ROW_NUMBER:12345
②DENSE_RANK:12223
③RANK:12225
-- ①对所有客户按订单总额进行排名
-- ②按区域和客户订单总额进行排名
-- ③找出订单总额排名前13位的客户
-- ④找出订单总额最高、最低的客户
-- ⑤找出订单总额排名前25%的客户
-- 筛选排名前12位的客户, table : user_order
-- 1.对所有客户按订单总额进行排名, 使用rownum , rownum = 13,14 的数据跟 12 的数据一样, 但是被漏掉了
select rownum, tmptb.* from (select * from user_order order by CUSTOMER_sales desc) tmptb where rownum <= 12;
-- 2.按区域和客户订单总额进行排名 Rank, Dense_rank, row_number
select region_id, customer_id, sum(customer_sales) total, rank() over(partition by region_id order by sum(customer_sales) desc) rank, dense_rank() over(partition by region_id order by sum(customer_sales) desc) dense_rank, row_number() over(partition by region_id order by sum(customer_sales) desc) row_number from user_order group by region_id, customer_id;
三、分析函数:Top/Bottom N、First/Last、NTile
-- ①对所有客户按订单总额进行排名
-- ②按区域和客户订单总额进行排名
-- ③找出订单总额排名前13位的客户
-- ④找出订单总额最高、最低的客户
-- ⑤找出订单总额排名前25%的客户
-- 此处 null 被排到第一位 , 可以加 nulls last 把null的数据放到最后
select region_id, customer_id, sum(customer_sales) cust_sales, sum(sum(customer_sales)) over(partition by region_id) ran_total, rank() over(partition by region_id order by sum(customer_sales) desc /* nulls last */) rank from user_order group by region_id, customer_id;
-- 找出所有订单总额排名前3的大客户
select * from
(select region_id,
customer_id,
sum(customer_sales) cust_total,
rank() over(order by sum(customer_sales) desc NULLS LAST) rank
from user_order
group by region_id, customer_id)
where rank <= 3;
-- 找出每个区域订单总额排名前3的大客户
select *
from (select region_id,
customer_id,
sum(customer_sales) cust_total,
sum(sum(customer_sales)) over(partition by region_id) reg_total,
rank() over(partition by region_id order by sum(customer_sales) desc NULLS LAST) rank
from user_order
group by region_id, customer_id)
where rank <= 3;
四、汇总
- 汇总
- 滚动汇总
- 分区滚动汇总
- 当前记录和后一条记录
- 分区汇总
Sum() Over ([Partition by ] [Order by ]) Sum() Over ([Partition by ] [Order by ] Rows Between Preceding And Following) Sum() Over ([Partition by ] [Order by ] Rows Between Preceding And Current Row) Sum() Over ([Partition by ] [Order by ] Range Between Interval "" "Day" Preceding And Interval "" "Day" Following )
五、Min()/Max():最大值/最小值
形式:
Min()/Max() Keep (Dense_rank First/Last [Partition by ] [Order by ])
- -- min keep first last 找出订单总额最高、最低的客户
- -- Min只能用于 dense_rank
- -- min 函数的作用是用于当存在多个First/Last情况下保证返回唯一的记录, 去掉会出错
- -- keep的作用。告诉Oracle只保留符合keep条件的记录。
select min(customer_id) keep (dense_rank first order by sum(customer_sales) desc) first, min(customer_id) keep (dense_rank last order by sum(customer_sales) desc) last from user_order group by customer_id;
-- 出订单总额排名前1/5的客户 ntile
-- 1.将数据分成5块
select region_id,customer_id, sum(customer_sales) sales, ntile(5) over(order by sum(customer_sales) desc nulls last) tile from user_order group by region_id, customer_id;
-- 2.提取 tile=1 的数据
select * from (select region_id,customer_id, sum(customer_sales) sales, ntile(5) over(order by sum(customer_sales) desc nulls last) tile from user_order group by region_id, customer_id) where tile = 1;
-- cust_nbr,month 为主键, 去重,只留下month最大的记录
-- 查找 cust_nbr 相同, month 最大的记录
select cust_nbr, max(month) keep(dense_rank first order by month desc) max_month from orders_tmp group by cust_nbr;
-- 去重, cust_nbr,month 为主键, cust_nbr 相同,只留下month最大的记录
delete from orders_tmp2 where (cust_nbr, month) not in (select cust_nbr, max(month) keep(dense_rank first order by month desc) max_month from orders_tmp2 tb group by cust_nbr)
五、first_value/last_value:首记录/末记录
形式:
First_value / Last_value(Sum() Over ([Patition by ] [Order by ] Rows Between Preceding And Following ))
六、lag()与lead():相邻记录
Lag(Sum(), 1) Over([Patition by ] [Order by ])
lag和lead函数可以在一次查询中取出同一字段的前n行的数据和后n行的值。这种操作可以使用对相同表的表连接来实现,不过使用lag和lead有更高的效率。
lag(arg1,arg2,arg3)
第一个参数是列名,
第二个参数是偏移的offset,
第三个参数是超出记录窗口时的默认值。
-- ①列出每月的订单总额以及全年的订单总额
-- ②列出每月的订单总额以及截至到当前月的订单总额
-- ③列出上个月、当月、下一月的订单总额以及全年的订单总额
-- ④列出每天的营业额及一周来的总营业额
-- ⑤列出每天的营业额及一周来每天的平均营业额
-- ①通过指定一批记录:例如从当前记录开始直至某个部分的最后一条记录结束
-- ②通过指定一个时间间隔:例如在交易日之前的前30天
-- ③通过指定一个范围值:例如所有占到当前交易量总额5%的记录
-- 列出每月的订单总额以及全年的订单总额
1.实现方法1
select month, sum(tot_sales) month_sales, sum(sum(tot_sales)) over (order by month rows between unbounded preceding and unbounded following) total_sales from orders group by month;
2.实现方法2
select month, sum(tot_sales) month_sales, sum(sum(tot_sales)) over(/*order by month*/) all_sales -- 加上Order by month , 则数逐条记录递增 from orders group by month;
-- 列出每月的订单总额以及截至到当前月的订单总额
1.实现方法1
select month, sum(tot_sales) month_sales, sum(sum(tot_sales)) over(order by month rows between unbounded preceding and current row) current_total_sales from orders group by month;
2.实现方法2
select month, sum(tot_sales) month_sales, sum(sum(tot_sales)) over(order by month) all_sales -- 加上Order by month , 则是前面记录累加到当前记录 from orders group by month;
-- 有时可能是针对全年的数据求平均值,有时会是针对截至到当前的所有数据求平均值。很简单,只需要将:
-- sum(sum(tot_sales))换成avg(sum(tot_sales))即可。
-- 统计当天销售额和五天内的平均销售额 range between interval
select trunc(order_dt) day,
sum(sale_price) daily_sales,
avg(sum(sale_price)) over (order by trunc(order_dt) range between interval "2" day preceding and interval "2" day following) five_day_avg
from cust_order
where sale_price is not null and order_dt between to_date("01-jul-2001","dd-mon-yyyy") and to_date("31-jul-2001","dd-mon-yyyy")
-- 显示当前月、上一个月、后一个月的销售情况,以及每3个月的销售平均值
select month, first_value(sum(tot_sales)) over (order by month rows between 1 preceding and 1 following) prev_month, sum(tot_sales) monthly_sales, last_value(sum(tot_sales)) over (order by month rows between 1 preceding and 1 following) next_month, avg(sum(tot_sales)) over (order by month rows between 1 preceding and 1 following) rolling_avg from orders_tmp where year = 2001 and region_id = 6 group by month order by month;
-- 显示当月的销售额和上个月的销售额
-- first_value(sum(tot_sales) over (order by month rows between 1 precedingand 0 following))
-- lag(sum(tot_sales),1)中的1表示以1月为间隔基准, 对应为lead
select month, sum(tot_sales) monthly_sales, lag(sum(tot_sales), 1) over (order by month) prev_month_sales from orders_tmp where year = 2001 and region_id = 6 group by month order by month;
七、rollup()、cube()和grouping():排列组合分组
1)、group by rollup(a, b, c):
首先会对(a、b、c)进行group by,然后再对(a、b)进行group by,其后再对(a)进行group by,最后对全表进行汇总操作。
2)、group by cube(a, b, c):
则首先会对(a、b、c)进行group by,然后依次是(a、b),(a、c),(a),(b、c),(b),(c),最后对全表进行汇总操作。
八、ratio_to_report ():计算每条记录在其对应记录集或其子集中所占的比例。
ratio_to_report(a) over(partition by b) :求按照b分组后a的值在所属分组中总值的占比,a的值必须为数值或数值型字段。
Ratio_to_report() 括号中就是分子,over() 括号中就是分母 分母缺省就是整个占比
eg:列出上一年度每个月的销售总额、年底销售额以及每个月的销售额占全年总销售额的比例:
select region_id, salesperson_id, sum(tot_sales) sp_sales, round(ratio_to_report(sum(tot_sales)) over (partition by region_id), 2) sp_ratio from orders where year = 2001 group by region_id, salesperson_id order by region_id, salesperson_id;
到此这篇关于Oracle分析函数的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。
相关文章:
 网公网安备
网公网安备