ORACLE正则匹配查询LIKE查询多个值检索数据库对象
字符串’^198[0-9]$’可以匹配‘1980-1989’,如果希望统计出公司那些员工是80年~89年入职的,就可以使用如下的SQL语句:
select * from emp e where regexp_like(to_char( e.hiredate,"yyyy"),"^198[0-9]$");
正则表达式中常用到的元数据(metacharacter)如下:
^ 匹配字符串的开头位置。
$ 匹配支付传的结尾位置。
* 匹配该字符前面的一个字符0次,1次或者多次出现。例如52*oracle 可以匹配 5oracle,52oracle,522oracle,5222oracle等等。
+ 匹配该字符前面的一个字符1次或者多次出现。例如52+oracle 可以匹配 52oracle,522oracle,5222oracle等等
? 匹配该字符前面的一个字符0次或1次或者多次出现。例如52?oracle 只能匹配5oracle,52oracle等等
{n} 匹配一个字符串n次,n为正整数。例如:hel{2}o 所匹配的是hello
{n,m} 匹配一个字符串至少n次,至多m次。其中n和m都是整数。
. 匹配除了null之外的任何单个字符串
(pattern) 这个是用来匹配指定模式的一个子表达式
x|y 匹配x或者y,其中x和y是一个或者多个字符
[abc] 匹配括号中的任意一个字符。例如:[ab]bc可以匹配abc和bbc
[a-z] 匹配指定范围内的任意字符串。例如[A-G]hi可以匹配Ahi至Ghi
[::]指定一个字符类,可以匹配该类中的任意字符 这里的字符类包括:
[:alphanum:] 可以匹配字符0-9、A-Z、a-z
[:alpha:]可以匹配字符A-Z、a-z
[:blank:]可以匹配空格或者tab键
[:digit:]可以匹配数字 0-9
[:gragh:]可以匹配非空字符
[:punct:]可以匹配. , ” ‘等标点符号。
[:upper:]可以匹配字符A-Z
[:lower:]可以匹配字符a-z
关于orace中的正则表达式只能通过oracle特意为正则表达式设计的4个函数来使用。这4个函数分别是:
regexp_like,regexp_instr,regexp_replace,regexp_substr。
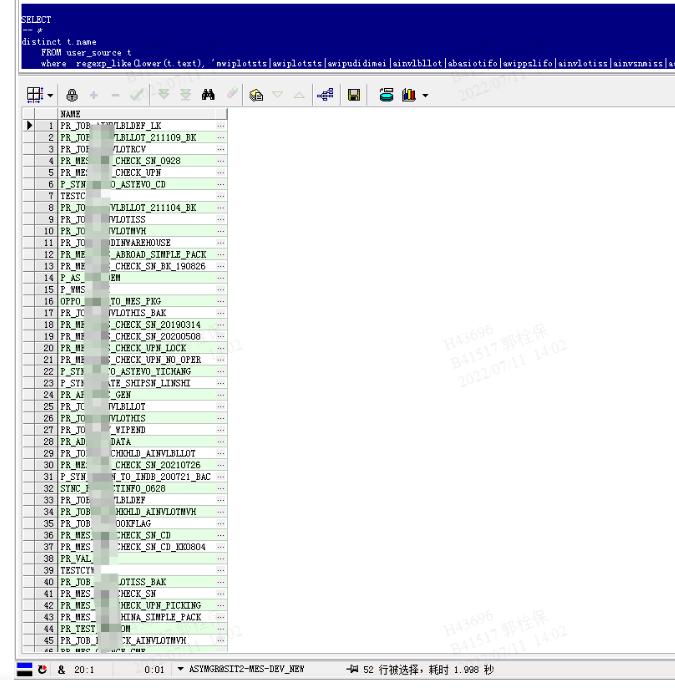
查询oracle中,哪些对象的sql包括了检索的文本(多个值 使用“|”隔开, 关于user_source对象,移步到无限套娃链接 ORACLE常用数据字典)

未去重(查询出详细信息):
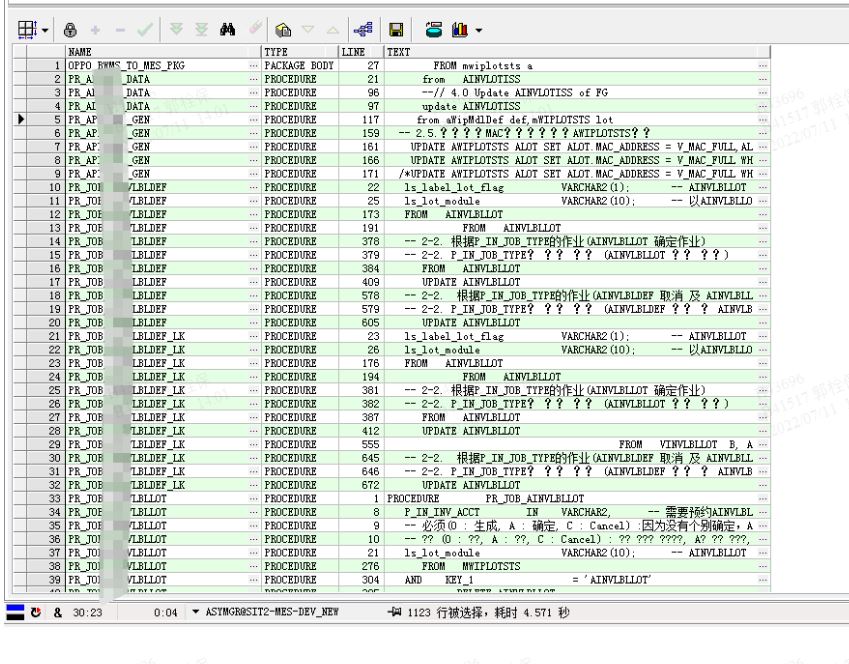
去重查询出涉及到的对象名称:
到此这篇关于ORACLE正则匹配查询,LIKE查询多个值检索数据库对象。的文章就介绍到这了,更多相关oracle正则匹配查询内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
 网公网安备
网公网安备