Mysql 删除重复数据保留一条有效数据(最新推荐)
浏览:7日期:2023-02-05 11:01:12
目录
- Mysql 删除重复数据保留一条有效数据
- 一、Mysql 删除重复数据,保留一条有效数据
- 二、Mysql 删除重复数据(多个字段分组)
- 三、Mysql 查询出可以删除的重复数据
- 补充:mysql删除重复记录并且只保留一条
- MySql如何删除所有多余的重复数据 需要处理的数据,如:
Mysql 删除重复数据保留一条有效数据
一、Mysql 删除重复数据,保留一条有效数据
DELETE FROM SZ_Building WHERE id NOT IN (
SELECT t.min_id FROM (
SELECT MIN(id) AS min_id FROM SZ_Building GROUP BY BLDG_NO
) t
)
;
原理:
根据字段对数据进行分组,查询出所有分组的最小ID(即要保留的不重复数据)将查询出来的数据(所有不重复的数据)存放到临时表中从原来的表中删除ID不在临时表中的重复数据
二、Mysql 删除重复数据(多个字段分组)
DELETE FROM SZ_Water_Level WHERE id NOT IN (
SELECT t.min_id FROM (
SELECT MIN(id) AS min_id FROM SZ_Water_Level GROUP BY CZBM,SJ,SW
) t
)
;
三、Mysql 查询出可以删除的重复数据
SELECT * FROM SZ_Building WHERE BLDG_NO IN ( SELECT BLDG_NO FROM SZ_Building GROUP BY BLDG_NO HAVING COUNT(1)>1 ) AND id NOT IN ( SELECT MIN(id) FROM SZ_Building GROUP BY BLDG_NO HAVING COUNT(1)>1 ) ;
补充:mysql删除重复记录并且只保留一条
准备的测试表结构及数据
插入的数据中A,B,E存在重复数据,C没有重复记录
CREATE TABLE `tab` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tab
-- ----------------------------
INSERT INTO `tab` VALUES ("1", "A");
INSERT INTO `tab` VALUES ("2", "A");
INSERT INTO `tab` VALUES ("3", "A");
INSERT INTO `tab` VALUES ("4", "B");
INSERT INTO `tab` VALUES ("5", "B");
INSERT INTO `tab` VALUES ("6", "C");
INSERT INTO `tab` VALUES ("7", "B");
INSERT INTO `tab` VALUES ("8", "B");
INSERT INTO `tab` VALUES ("9", "B");
INSERT INTO `tab` VALUES ("10", "E");
INSERT INTO `tab` VALUES ("11", "E");
INSERT INTO `tab` VALUES ("12", "E");
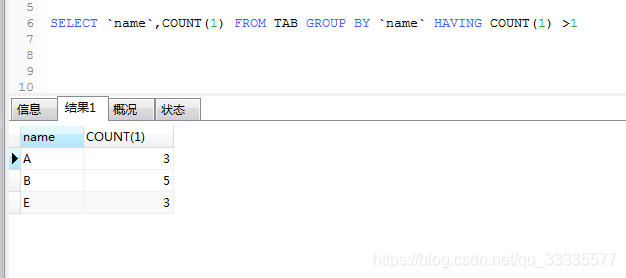
使用HAVING关键字筛选出表中重复数据
SELECT `name`,COUNT(1) FROM TAB GROUP BY `name` HAVING COUNT(1) >1
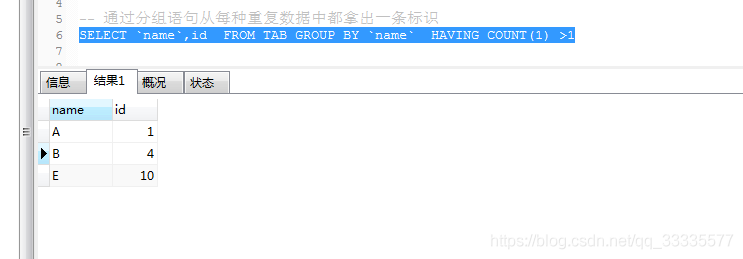
可以通过分组语句从每种重复数据中都拿出一条标识
SELECT `name`,id FROM TAB GROUP BY `name` HAVING COUNT(1) >1
删除重复记录并且只保留一条 [留意SQL注释]
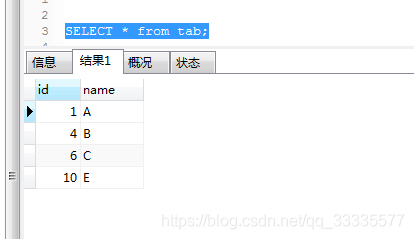
DELETE from tab where -- 删除所有的重复时间 Begin -- `name` in ( SELECT * from (SELECT `name`FROM TAB GROUP BY `name` HAVING COUNT(1) >1) tmp2 ) -- 删除所有的重复时间 END -- -- 但一些特定ID的记录不进行删除 Begin -- AND id NOT in( select id from ( SELECT `name`,id FROM TAB GROUP BY `name` HAVING COUNT(1) >1 ) tmp1 ) -- 但一些特定ID的记录不进行删除 END --

执行后最终结果
方法二
MySql如何删除所有多余的重复数据
方法一查询出的所有多余的重复记录:
方法二查询出的所有多余的重复记录(与方法一的结果相同):
方法三查询出的所有多余的重复记录:这里方法三因为用了MAX()方法(也可改用MIN()),查询结果记录的id不太一样,但也可以被视为重复多余的数据,关键是你希望选择保留哪一条记录而已。
MySql如何删除所有多余的重复数据 需要处理的数据,如:
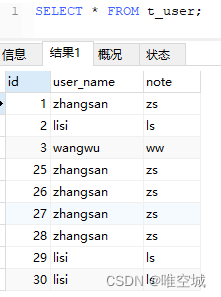
出现重复的数据,如:
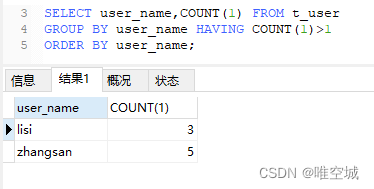
先用SELECT查询看看结果:
-- 方法一 SELECT * FROM t_user WHERE user_name IN ( SELECT user_name FROM t_user GROUP BY user_name HAVING COUNT(1)>1 ) AND id NOT IN ( SELECT MIN(id) FROM t_user GROUP BY user_name HAVING COUNT(1)>1 )
方法一查询出的所有多余的重复记录:
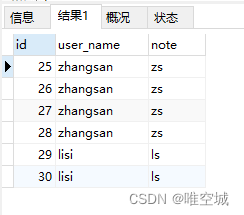
-- 方法二 SELECT * FROM t_user WHERE id NOT IN ( SELECT MIN(id) FROM t_user GROUP BY user_name )
方法二查询出的所有多余的重复记录(与方法一的结果相同):
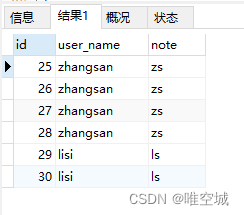
-- 方法三 SELECT * FROM t_user AS t1 WHERE t1.id <> ( SELECT MAX(t2.id) FROM t_user AS t2 WHERE t1.user_name=t2.user_name )
方法三查询出的所有多余的重复记录:
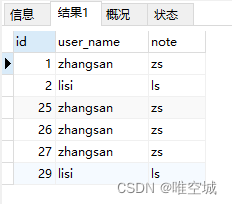
这里方法三因为用了MAX()方法(也可改用MIN()),查询结果记录的id不太一样,但也可以被视为重复多余的数据,关键是你希望选择保留哪一条记录而已。
下面是对上面的SELECT语句稍作修改并加入了DELETE
-- 方法一(笨方法但容易理解)
DELETE FROM t_user WHERE user_name IN (
SELECT t1.user_name FROM (
-- 查询出所有重复的user_name
SELECT user_name FROM t_user GROUP BY user_name HAVING COUNT(1)>1
) t1
)
AND id NOT IN (
SELECT t2.min_id FROM (
-- 查询出所有重复的记录并各自只取其中一条(MIN(id)或MAX(id)都可以)
SELECT MIN(id) AS min_id FROM t_user GROUP BY user_name HAVING COUNT(1)>1
) t2
)
-- 方法二(推荐方法也容易理解)
DELETE FROM t_user WHERE id NOT IN (
SELECT t.min_id FROM (
-- 过滤出重复多余的数据,比如,如果所有记录中存在1条记录是user_name=zhangsan的,那么就取出它;
-- 如果所有记录中存在多条记录是user_name=lisi的,那么只取其中1条,其他的不查询出来
SELECT MIN(id) AS min_id FROM t_user GROUP BY user_name
) t
)
-- 方法三(推荐方法但不太容易理解)
DELETE FROM t_user WHERE id IN (
SELECT t.id FROM (
-- 1. 关于所有存在相同user_name的记录,只查询出(保留)重复记录中的1条,假设这样查询出来的集合为A集合。
-- 2. 在所有记录中,只要id不在A集合中的,都把它们查询出来
SELECT t1.id FROM t_user AS t1 WHERE t1.id <> (SELECT MAX(t2.id) FROM t_user AS t2 WHERE t1.user_name=t2.user_name)
) t
)
-- 或
DELETE FROM t_user t1
WHERE t1.id <> (
SELECT t2.max_id FROM (
SELECT MAX(t3.id) AS max_id FROM t_user t3 WHERE t1.user_name=t3.user_name
) t2
)
最后删除成功之后,显示数据已经没有重复的了
到此这篇关于Mysql 删除重复数据保留一条有效数据的文章就介绍到这了,更多相关Mysql 删除重复数据内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
标签:
MySQL
上一条:mysql时间相减如何获取秒值下一条:MySQL查看锁的实现代码
 网公网安备
网公网安备