SQL Server删除表中的重复数据
浏览:6日期:2023-02-22 14:52:23
添加示例数据
create table Student(
ID varchar(10) not null,
Name varchar(10) not null,
);
insert into Student values("1", "zhangs");
insert into Student values("2", "zhangs");
insert into Student values("3", "lisi");
insert into Student values("4", "lisi");
insert into Student values("5", "wangwu");
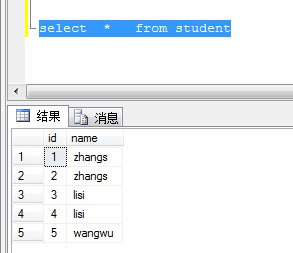
删除Name重复多余的行,每个Name仅保留1行数据
1、查询表中Name 重复的数据
select Name from Student group by Name having count(Name) > 1

2、有唯一列,通过唯一列最大或最小方式删除重复记录
检查表中是否有主键或者唯一值的列,当前可以数据看到ID是唯一的,可以通过Name分组排除掉ID最大或最小的行
delete from Student where Name in( select Name from Student group by Name having count(Name) > 1) and ID not in(select max(ID) from Student group by Name having count(Name) > 1 )
执行删除脚本后查询
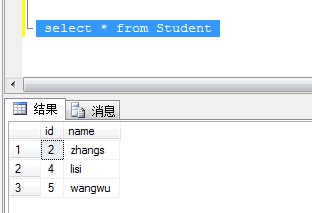
3、无唯一列使用ROW_NUMBER()函数删除重复记录
如果表中没有唯一值的列,可以通过row_number 来删除重复数据
重复执行插入脚本,查看表数据,表中没有唯一列值
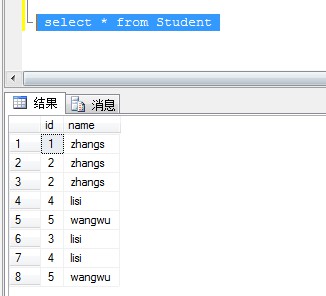
Delete T From (Select Row_Number() Over(Partition By [Name] order By [ID]) As RowNumber,* From Student)T Where T.RowNumber > 1
小知识点
语法:ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)
表示根据COLUMN分组,在分组内部根据 COLUMN排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
函数“Row_Number”必须有 OVER 子句。OVER 子句必须有包含 ORDER BY
Row_Number() Over(Partition By [Name] order By [ID]) 表示已name列分组,在每组内以ID列进行升序排序,每组内返回一个唯一的序号
执行删除脚本后查询表数据
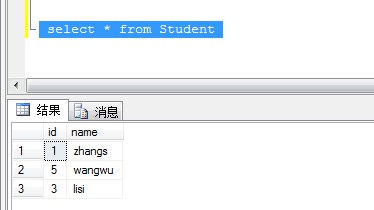
到此这篇关于SQL Server删除表中重复数据的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。
标签:
MsSQL
相关文章:
1. Can’t connect to MySQL server on ’localhost’ (10048)2. SQL Server系统函数介绍3. SQL Server开发智能提示插件SQL Prompt介绍4. SQL Server序列SEQUENCE用法介绍5. 轻量级数据库SQL Server Express LocalDb介绍6. SQL Server2019安装的详细步骤实战记录(亲测可用)7. SQL Server数据库备份和恢复数据库的全过程8. SQL Server备份数据库的完整步骤9. SQL Server实现查询每个分组的前N条记录10. 详解SQL Server 中的 ACID 属性
 网公网安备
网公网安备