SQLSERVER 临时表和表变量的区别汇总
目录
- 一:背景
- 1. 讲故事
- 二:到底有什么区别
- 1. 前置思考
- 2. 如何验证都存储在 tempdb 中 ?
- 3. 不同点在哪里
- 三:总结
一:背景
1. 讲故事
今天和大家聊一套面试中经常被问到的高频题,对,就是 临时表 和 表变量 这俩玩意,如果有朋友在面试中回答的不好,可以尝试看下这篇能不能帮你成功迈过。
二:到底有什么区别
1. 前置思考
不管是 临时表 还是 表变量 都带了 表 这个词,既然提到了 表 ,按推理自然会落到某一个 数据库 中,如果真在一个 数据库 中,那自然就有它的存储文件 .mdf 和 .ldf,那是不是如我推理的那样呢? 查阅 MSDN 的官方文档可以发现,临时表 和 表变量 确实都会使用 tempdb 这个临时存储数据库,而且 tempdb 也有自己的 mdf,ndf,ldf 文件,截图如下:
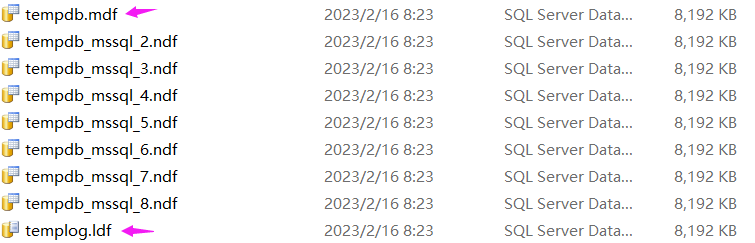
有了这个大思想之后,接下来就可以进行验证了。
2. 如何验证都存储在 tempdb 中 ?
要想验证其实很简单,sqlserver 提供了多种方式观察。
- 查询的过程中观察 tempdb 下是否存在
xxx表。 - 使用动态管理视图
sys.dm_db_session_space_usage查询当前sql占用tempdb下的数据页个数。
为了让测试效果明显,我分别插入 10w 条记录观察 数据页 占用情况。
1.临时表插入 10w 条记录
CREATE TABLE #temp
(
id INT,
content CHAR(4000) DEFAULT "aaaaaaaaaa"
);
GO
INSERT INTO #temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
GO
SELECT * FROM sys.dm_db_session_space_usage
WHERE session_id=@@SPID;

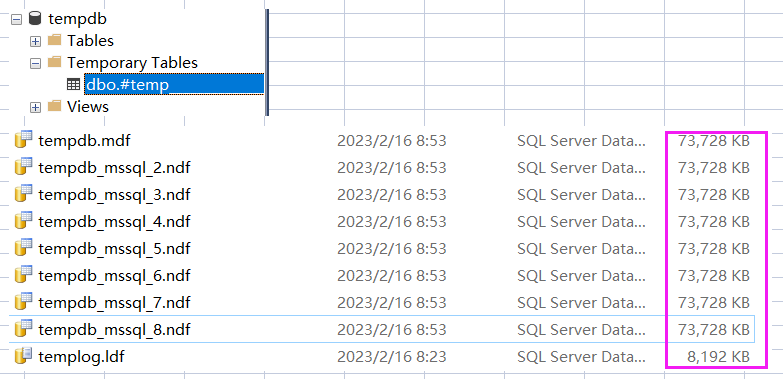
从图中的 user_objects_alloc_page_count=50456 看,当前的 insert 操作占用了 50456 个数据页。
接下来展开 tempdb 数据库以及观察到的 mdf 文件大小,都验证了存储到 tempdb 这个结论。
2.表变量插入 10w 条记录
因为表变量的特殊性,这里我故意暂停 1min 让查询迟迟得不到结束,在这期间方便展开 tempdb,重启 sqlserver 恢复初始状态后,执行如下 sql:
DECLARE @temp TABLE
(
id INT,
content CHAR(4000) DEFAULT "aaaaaaaaaa"
);
INSERT INTO @temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
SELECT * FROM sys.dm_db_session_space_usage
WHERE session_id=@@SPID;
WAITFOR DELAY "00:01:00"
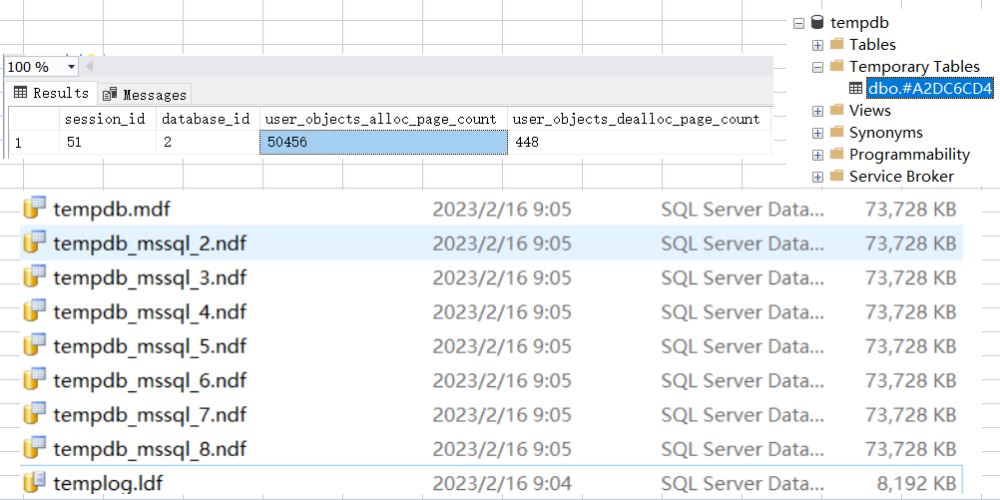
从图中可以看到 表变量 也会占用 5w+ 的数据页并且数据文件会膨胀。
3. 不同点在哪里
对底层存储有了了解之后,接下来按照重要度从高到低来了解一下区别吧。
1.临时表有统计信息,而表变量没有
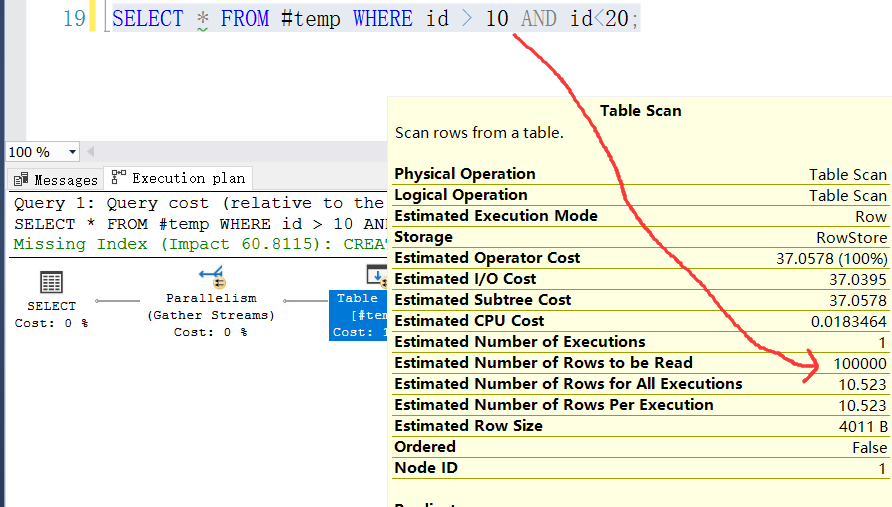
所谓的 统计信息,就是对表数据绘制一个 直方图 来掌握数据的分布情况,sqlserver 在择取较优的执行计划时会严重依赖于这个 直方图,由于展开不了 Statistics 列,这里就从执行计划上观察,如下图所示:
- 临时表下的执行计划
选中 SELECT * FROM #temp WHERE id > 10 AND id<20; 之后点击 SSMS 的评估执行计划按钮来观察下评估执行计划,可以清晰的看到 sqlserver 知道表中有多少条记录,截图如下:
- 表变量下的执行计划
由于表变量的批处理性,我们用 SET STATISTICS XML ON 把 xml 查询出来,然后点击观察可视化视图,参考sql 如下:
DECLARE @temp TABLE
(
id INT,
content CHAR(4000) DEFAULT "aaaaaaaaaa"
);
INSERT INTO @temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
SET STATISTICS XML ON
SELECT * FROM @temp WHERE id > 10 AND id<20;
SET STATISTICS XML OFF
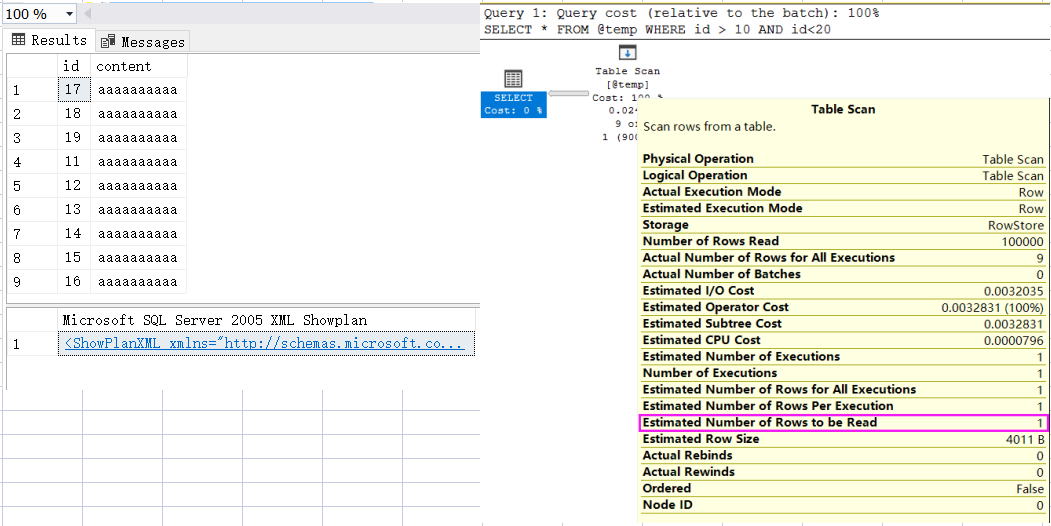
从图中可以清晰的看到,虽然表变量有 10w 条记录,但由于没有统计信息,sqlserver 也就无法知道这张表的数据分布,所以就按照默认值 1 条来计算。
从这里大家也能看得出来,如果 表记录 的真实条数 和 默认的 1 严重偏移的话,会给生成执行计划 造成重大失误,这个大家一定要当心了。
2.其它使用上的区别
除了上一个本质上的不同,接下来就是一些使用上的不同了,比如:
- 临时表是 session 级的,表变量是 批处理 级
所谓的批处理,就是以 go 为界定,两者就是作用域上的不同。
- 临时表可以后续修改,表变量不能后续修改。
这里的修改涉及到 字段,索引,整体上来说临时表在使用上和普通表趋同,表变量不能进行后续修改。
三:总结
总的来说,表变量 没有统计信息,也不可以后续做 DDL 操作,这种情况下 表变量 比 临时表 更轻量级,不会有如下副作用:
- DDL 修改导致执行计划过期重建
- sqlserver 对 统计信息 的维护压力
其实在这种作用域下高频的创建和删除表的操作中,表变量会让系统压力减轻很多。
但阳事总会有阴事来均衡它,一旦 表变量 的记录条数严重偏移默认的 1条,会污染sqlserver的执行计划择取,可能会让你的 sql 遭受灭顶之灾,所以一定要控制 表变量 的记录条数,最好在百条内 。
最后的建议是:如果你是个小白可以无脑使用 临时表 ,90%的情况下都可以做到通杀,如果你是个高手可以考虑一下 表变量。
到此这篇关于SQLSERVER 临时表和表变量到底有什么区别的文章就介绍到这了,更多相关SQLSERVER 临时表和表变量区别内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!

 网公网安备
网公网安备