一次tomcat源码启动控制台中文乱码的调试过程记录
发现问题
今天准备学习下tomcat源码,于是从官网下载了tomcat的源码,导入到IDEA中,使用maven工具build完项目之后,启动项目,控制台打印了tomcat日志,但是中文都是乱码。
一开始我怀疑是IDEA的问题,于是在网上找了各种解决办法尝试。大致有这几种:
1、修改run/debug configurations,添加VM options参数:-Dfile.encoding=utf-8;
2、修改run/debug configurations,添加Enviroment variables参数:JAVA_TOOL_OPTIONS:-Dfile.encoding=utf-8和JAVA_OPTS:-Dfile.encoding=utf-8;
3、修改IDEA配置file encodings的3处编码为UTF-8;
4、修改IDEA的Custom VM options,添加-Dfile.encoding=utf-8;
5、修改IDEA的安装目录bin下的idea.exe.vmoptions和idea64.exe.vmoptions文件,添加-Dfile.encoding=utf-8;
6、修改项目下的.idea文件夹下的encodings.xml文件,不是UTF-8的改为UTF-8;
7、修改tomcat的配置文件logging.properties,将里面的UTF-8改为GBK;
8、修改完删除target文件夹重新编译;
9、修改完重启IDEA。
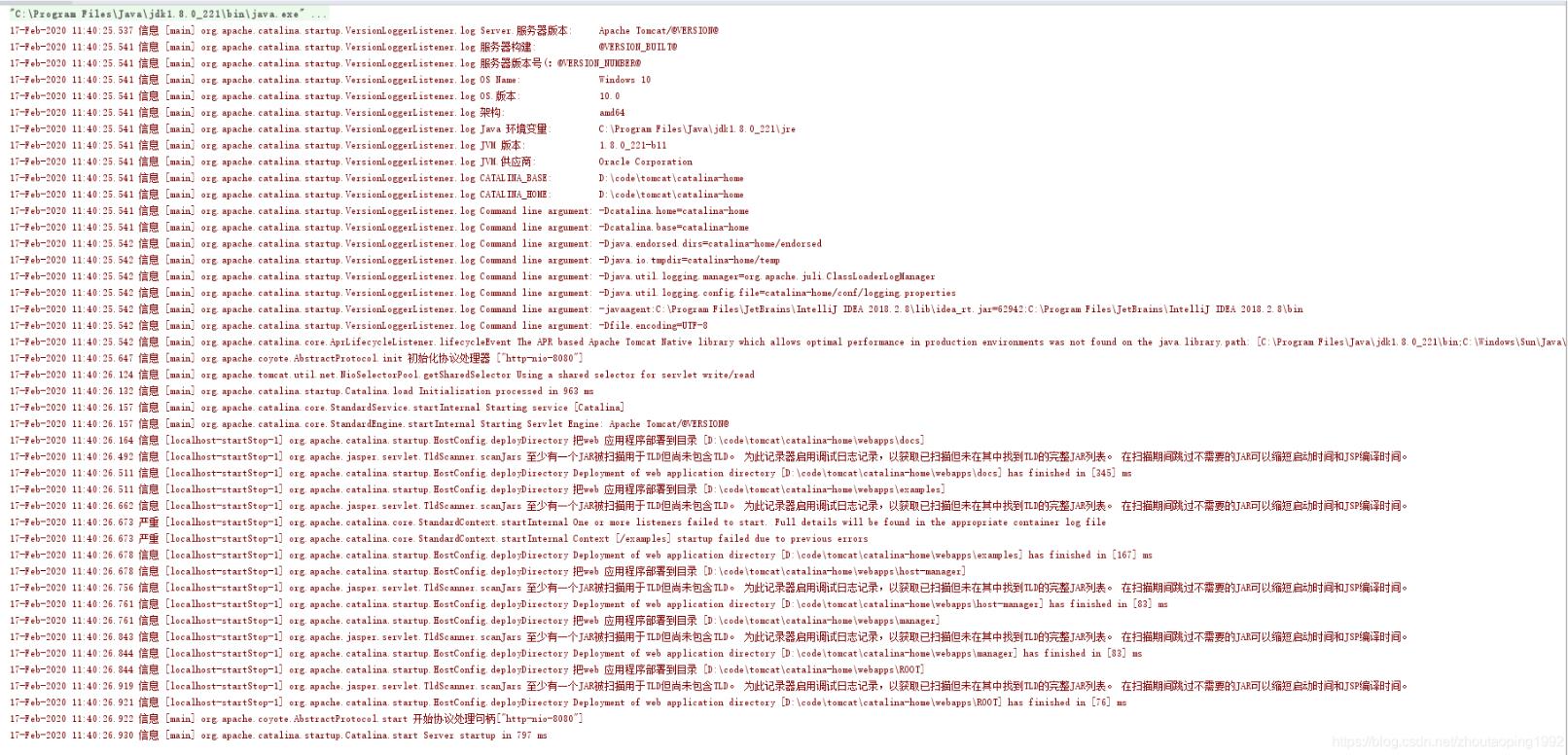
尝试完所有方法后,控制台日志乱码问题并没有解决,如图:

仔细观察后,发现日志左边的日志等级”信息”和”严重”之类的中文乱码解决了,但是日志中还有乱码。
感觉应该是代码的问题,于是决定debugger代码,先从日志的第一行开始。
17-Feb-2020 10:10:08.585 信息 [main] org.apache.catalina.startup.VersionLoggerListener.log Server.æœåŠ¡å™¨ç‰ˆæœ¬: Apache Tomcat/@VERSION@
找到org.apache.catalina.startup.VersionLoggerListener类的log()方法,打断点一步一步跟踪
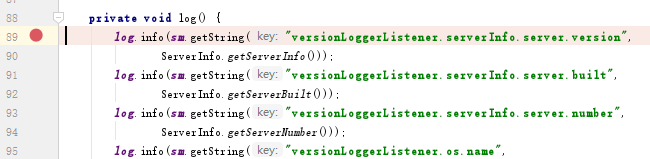
最终发现所有的值存在了PropertyResourceBundle类的lookup的map集合中,集合中的数据已经乱码了。
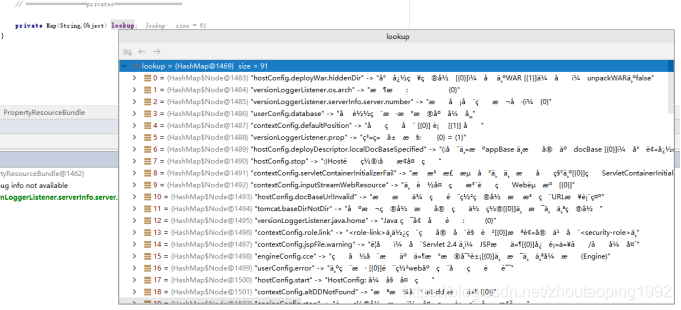
于是继续debugger查看lookup的加载,通过源码查看lookup集合中的数据是从properties文件中读取出来的。查看该properties文件编码也是UTF-8。于是继续查看源码。
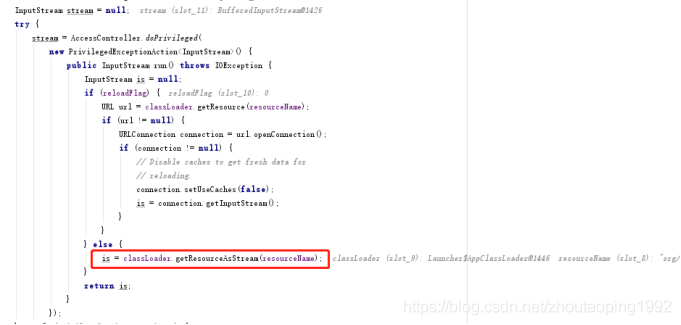
ResourceBundle中的is = classLoader.getResourceAsStream(resourceName);加载的这个properties文件

再通过PropertyResourceBundle构造方法加载的数据。
正准备修改这块代码时,发现这竟是JDK中的类,无法修改。(后来才知道ResourceBundle是用来做国际化的)。
后来查资料知道了:在java中, 读取文件的默认格式是iso8859-1, 而我们中文存储的时候一般是UTF-8. 所以导致读出来的是乱码。
解决方案有两种:
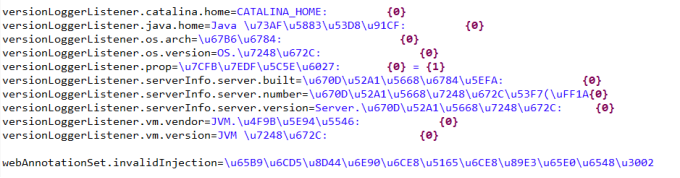
1、使用JDK下的工具native2ascii.exe将properties文件转为Unicode编码。转换后如图:
2、在代码中获取到了值之后手动重新编码解码下
try {
value = new String(value.getBytes("ISO-8859-1"), "UTF-8");
}catch(Exception e){
e.printStackTrace();
}
经过测试,两种方法都可以解决问题。
因为tomcat中properties文件过多,我采用了第二种方法,修改了tomcat源码,修改如下:
1)org.apache.tomcat.util.res.StringManager类中的getString(final String key, final Object... args)方法。
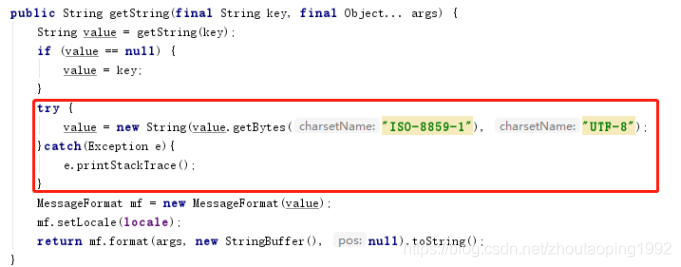
2)org.apache.jasper.compiler.Localizer类的getMessage(String errCode)方法
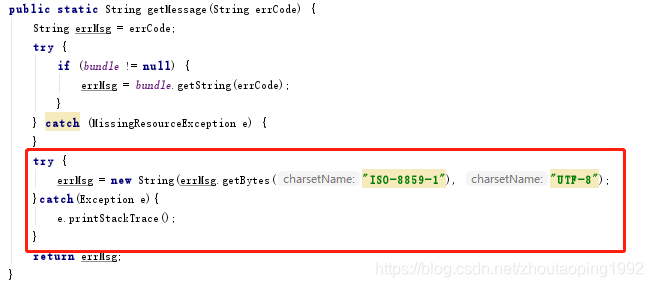
至此,乱码问题解决
总结
到此这篇关于一次tomcat源码启动控制台中文乱码调试过程记录的文章就介绍到这了,更多相关tomcat源码启动控制台中文乱码内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- 排行榜
- DNS服务器可能不可用的解决方法
- 1. win10下FTP服务器搭建图文教程
- 2. 阿里云windows server2019配置FTP服务的完整步骤
- 3. Linux系统 Centos7.4手动在线升级到Centos7.7
- 4. Linux服务器VPS的Windows DD包详细的制作教程
- 5. Linux系统配置(服务控制)详细介绍
- 6. 在CentOS7上搭建本地GitLab服务器
- 7. 在windows server 2012 r2中安装mysql的详细步骤
- 8. 解决ubuntu安装软件时,status-code=409报错的问题
- 9. Windows Server 2016远程桌面服务配置和授权激活(2个用户)
- 10. windows server 2019开启iis服务器+tp5.1的完美配置运行流程
 网公网安备
网公网安备