Zabbix对Kafka topic积压数据监控的解决方案
目录
- Kafka
- 需求
- 解决方案
- 1.监控分析
- 2.监控思路
- (1) 消费者组管理
- (2)分区自动发现
- (3)获取监控项“test-group/test/分区X”的Lag
- (4)最终脚本
- 3.Zabbix 自动发现配置
- 4.告警信息
Kafka
Apache Kafka是一个分布式发布-订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。
Kafka适合离线和在线消息消费。
Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。Kafka构建在ZooKeeper同步服务之上。它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
需求
虽然我们在生产环境中可以使用Kafka对业务进行解耦,但这并不意味着业务系统就高枕无忧了。消费者的消费速度是否能够匹配生产速度、过多的消息积压这些都可能影响业务系统的正常运行。
关于业务系统运行状态,虽然我们可以通过业务监控来确定,但是业务监控一般是要对数据进行聚合分析并达到一定的阈值才能触发告警。因此业务监控告警通知时,业务实际已经有问题一段时间了。为应对这种情况,我们一般需要和系统监控进行互补。系统监控会周期性的对硬件、网络、服务器、应用等不同维度进行监控告警,一旦某个组件的状态有问题,那么系统监控会先预警,然后业务系统才可能进一步预警。经过不同监控系统的告警升级,才更能准确的反映业务系统的运行状态。
话说回来,对于上线后的Kafka集群,我们除了要对服务的可用性进行监控外,还要对Topic的消费情况进一步监控。
解决方案
1.监控分析
Lag作为监控指标,它直接反映了一个消费者的运行情况。一个正常工作的消费者,它的Lag值应该很小,甚至是接近于0的,这表示该消费者能够及时地消费生产者生产出来的消息,滞后程度很小。
因此我们将Topic作为我们的监控项,当相关的Topic Lag达到某一阈值时进行多渠道告警。
另经过Kafka运行机制的我们知道:
- 每个Topic内部需要按照Partition进行再次分区
- 同一个topic的partition只能由同一个消费者组(group)内的一个consumer来消费,分区数决定了同组消费者个数的上限
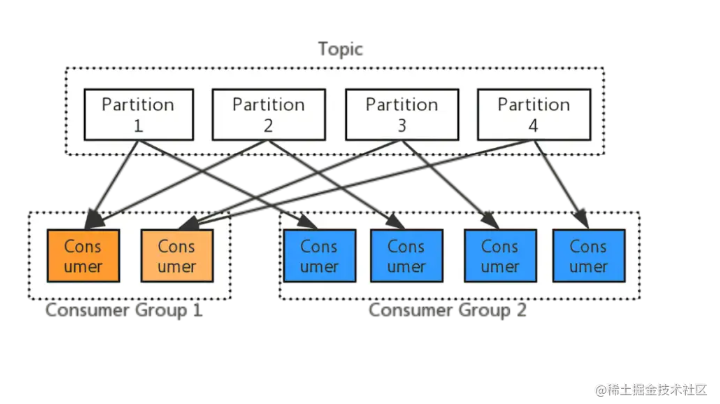
通过以上“Topic-Partition-消费者组(group)”之间的关系,为了便于我们通过告警信息更快的定位故障点:
- 监控项命名规则:消费者组(Group)/Topic/Partition,三者组成唯一的监控项;
- 监控项Lag值:获取业务系统中某个消费者组的特定Topic所有分区的Lag值进行告警;
2.监控思路
(1) 消费者组管理
通过Kafka自带的kafka-consumer-groups.sh脚本,我们可以轻松获取查看指定消费组 消费的所有Topic、及所在分区、最新消费offset、Log最新数据offset、Lag还未消费数量、消费者ID等等信息
# 查看消费者组的topic 消费状态 bash kafka-consumer-groups.sh --bootstrap-server 192.168.3.55:9090 --describe --group test2_consumer_group TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID test 0 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1 test 1 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1 test 2 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1 test 3 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1
(2)分区自动发现
对于Kafka topic的监控我们使用Zabbix监控平台,考虑到后续业务系统的持续性接入,我们通过Zabbix自动发现实现对特定消费者组(Group)和Topic下所有分区自动发现:
# 自动发现
vim consumer-groups.conf
#按消费者组(Group)|Topic格式,写入自动发现配置文件
test-group|test
# 执行脚本自动发现指定消费者和topic的分区
bash consumer-groups.sh discovery
{
"data": [
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"0" },
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"1" },
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"3" },
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"2" }
]
}
自动发现中的GROUP、TOPIC、PARTITION 这三个信息可以用于进一步过滤不同的分区的Lag值和监控系统中的监控项名称:
- test-group/test/分区0
- test-group/test/分区1
- test-group/test/分区2
- test-group/test/分区3
- 等其他 test-group/test相关的所有分区
(3)获取监控项“test-group/test/分区X”的Lag
# 获取分区0 lag bash consumer-groups.sh lag 0 # 获取分区1 lag bash consumer-groups.sh lag 1 # 获取分区2 lag bash consumer-groups.sh lag 2 # 获取分区3 lag bash consumer-groups.sh lag 3
(4)最终脚本
vim consumer-groups.sh
#!/bin/bash
#comment: 根据消费者组监控topic lag,进行监控告警
#配置文件说明
#消费者组|Topic
#test-group|test
#获取topic 信息
cal_topic() {
if [ $# -ne 2 ]; then
echo "parameter num error, 读取topic信息失败"
exit 1
else
/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.3.55:9092 --describe --group $1 |grep -w $2
fi
}
#topic+分区自动发现
topic_discovery() {
printf "{\n"
printf "\t\"data\": [\n"
for line in `cat /data/scripts/consumer-groups.conf`
do
group=`echo ${line} | awk -F"|" "{print $1}"`
topic=`echo ${line} | awk -F"|" "{print $2}"`
cal_topic $group $topic > /tmp/consumer-group-tmp
count=`cat /tmp/consumer-group-tmp|wc -l`
n=0
while read line
do
n=`expr $n + 1`
#判断最后一行
if [ $n -eq $count ]; then
topicp=`echo $line | awk "{print $1}"`
partition=`echo $line | awk "{print $2}"`
printf "\t\t{ \"{#GROUP}\":\"${group}\", \"{#TOPICP}\":\"${topicp}\", \"{#PARTITION}\":\"${partition}\" }\n"
else
topicp=`echo $line | awk "{print $1}"`
partition=`echo $line | awk "{print $2}"`
printf "\t\t{ \"{#GROUP}\":\"${group}\", \"{#TOPICP}\":\"${topicp}\", \"{#PARTITION}\":\"${partition}\" },\n"
fi
done < /tmp/consumer-group-tmp
done
printf "\t]\n"
printf "}\n"
}
if [ $1 == "discovery" ]; then
topic_discovery
elif [ $1 == "lag" ];then
cat /tmp/consumer-group-tmp |awk -v p=$2 "{if($2==p){print $5}}"
else
echo "Usage: /data/scripts/consumer-group.sh discovery | lag"
fi
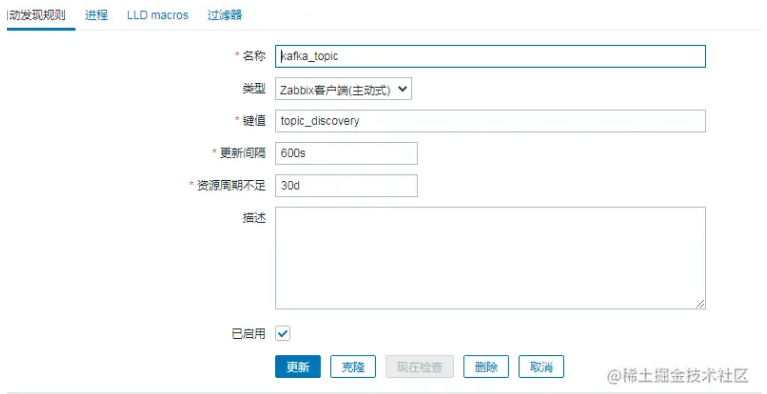
3.Zabbix 自动发现配置
1.自动发现配置
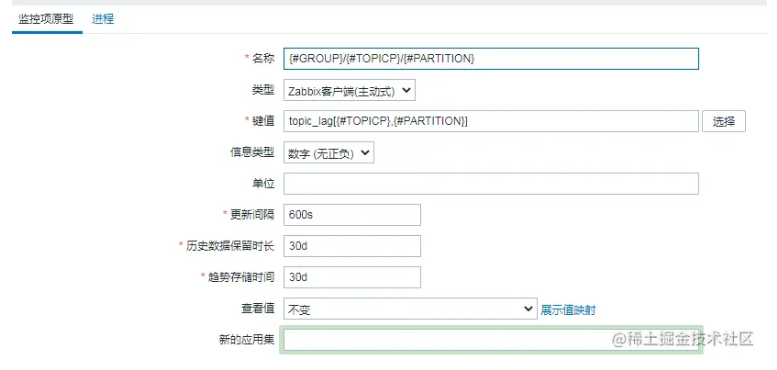
2.监控项原型 通过消费者组、Topic、Partition 组成监控项名称,告警信息中的名称能够帮助我们快定位故障点。
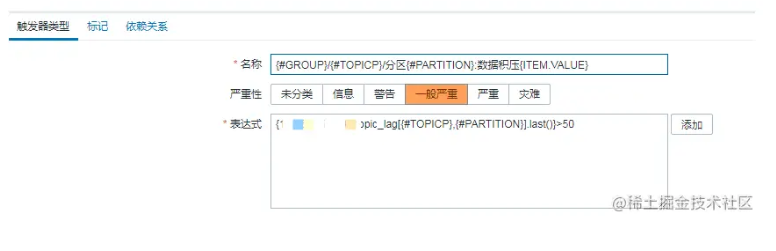
3.触发器 我们lag的初始阈值设置为50,可根据时间情况进行调整。
4.告警信息
告警主机:Kafka_192.168.3.55 主机IP:192.168.3.55 主机组:Kafka 告警时间:2022.03.21 00:23:10 告警等级:Average 告警信息:test-group/test/分区1:数据积压62 告警项目:topic_lag[test,1] 问题详情: test-group/test/1: 62
到此这篇关于Zabbix对Kafka topic积压数据监控的文章就介绍到这了,更多相关Zabbix Kafka 监控内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- 排行榜
- DNS服务器可能不可用的解决方法
- 1. Nginx error_page自定义错误页面设置过程
- 2. Nginx配置Tcp负载均衡的方法
- 3. IIS7 IIS8 http自动跳转到HTTPS(80端口跳转443端口)
- 4. Linux系统 Centos7.4手动在线升级到Centos7.7
- 5. windows server 2019 无法安装AMD Radeon RX 6600 XT显卡驱动的解决方法
- 6. 在CentOS7上搭建本地GitLab服务器
- 7. win10下FTP服务器搭建图文教程
- 8. Linux服务器VPS的Windows DD包详细的制作教程
- 9. 阿里云windows server2019配置FTP服务的完整步骤
- 10. Windows 2008任务计划执行bat脚本失败返回0x1的解决方法
 网公网安备
网公网安备